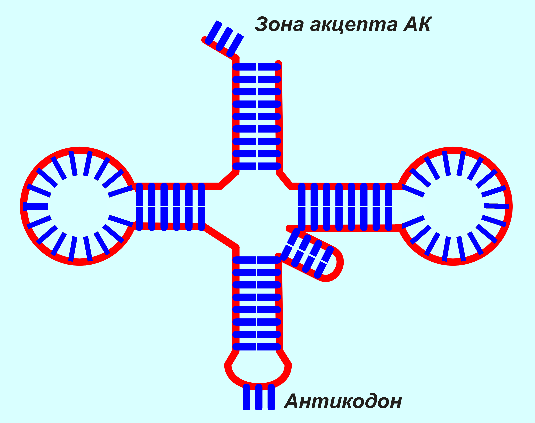
|
На следующем
этапе самопроизвольных преобразований нуклеотиды урацилового ряда выстраиваются
в цепочки так называемых РНК - рибонуклеиновых кислот.
(Именно по первой букве этого слова в латинском начертании все радикалы
и комплексы урацилового ряда и имеют индекс r . Кроме самоочевидного
урацила.)
Нуклеотиды
противоположного семейства ("обескисленных" радикалов и нейтральных
универсальных азотистых оснований) могут выстраиваться (и постоянно
успешно делают это) в продольные нити будущих ДНК - дезокси-рибонуклеиновых
кислот. (Это длинное слово здесь написано через дефис только для удобства
правильного его первого прочтения. По первой букве этих кислот все исходные
радикалы этого ряда имеют индекс d . Кроме стоящего особняком
тимина.)
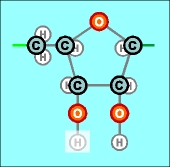
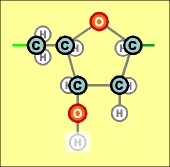
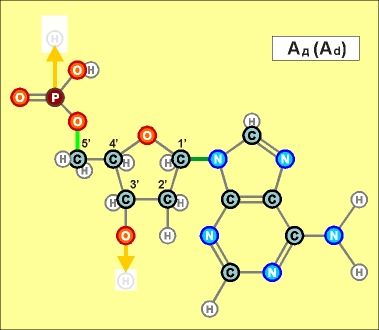
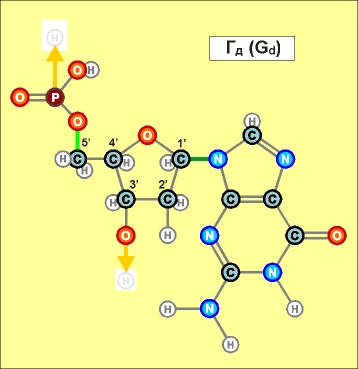
На предыдущих
схематических рисунках нуклеотидов бледным
цветом были показаны атомы, в направлении которых каждый нуклеотид сильно
поляризован, потому что с одной его стороны почти по одной прямой линии
расположено сразу три атома кислорода, а с другой (после третьего атома
углерода С 3' ) - только один.
Имеющийся
у всех нуклеотидов уринового ряда еще один атом кислорода, возле атома
С 2' карбоновой пентозы, как раз этим дополнительным атомом углерода
и нейтрализован (как другая возможная точка поляризации). Более того, "лишний" атом кислорода только немного перераспределяет напряженность
электрического поля у атома С 3' , делая все продольные соединения нуклеотидов
этого ряда немного слабее.
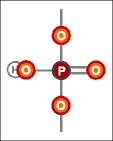
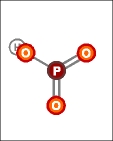
Так
или иначе, вертикальный (по рисункам) поляризованный участок любого
нуклеотида (Н)-ОРОССС-(ОН), или, в другой форме записи ("радикальной"),
-OPOCCCO- , является универсальным (и очень прочным!) продольным
соединителем, действующим по принципу электростатического притяжения.
К тому же, сблизившиеся за счет этого звенья укрепляют свое взаимодействие
еще и за счет создания совместных (частично) электронных оболочек.
Такое
взаимодействие неизбежно приводит к естественной (хотя и вполне спонтанной) полимеризации нуклеотидов - их соединению в длинные вертикальные
нити. Наличие большого количества свободных (одиночных) нуклеотидов
в органических растворах (в т.ч., и в так называемом первичном биологическом
бульоне) способствует этому процессу, а их дефицит тормозит его, но
принципиально абсолютно ничего в нем не меняет.
Нуклеотиды
обоих семейств очень быстро выстаиваться в очень длинные цепи, причем,
вначале (на стадии самообразования) - без какой-либо системы в этих
цепях, например:
...ТЦЦААТГГГЦЦТТАТГГГЦЦЦТТАТАТАГГАЦЦАТТ......
и т.д.
Длина такого
рода цепей может достигать десятков или сотен тысяч нуклеотидов (у бактерий
и простейших одноклеточных), а то и многих миллионов (или даже
миллиардов - у высших биологических видов). Причиной высокой степени
полимеризации (образования длинных нитей) является исключительно высокая
прочность продольных соединителей.
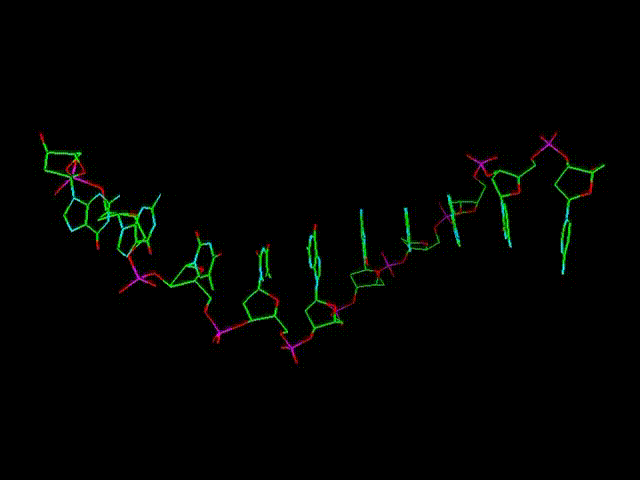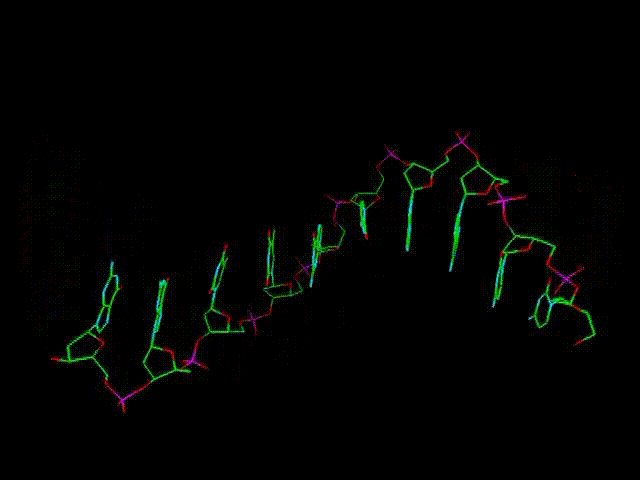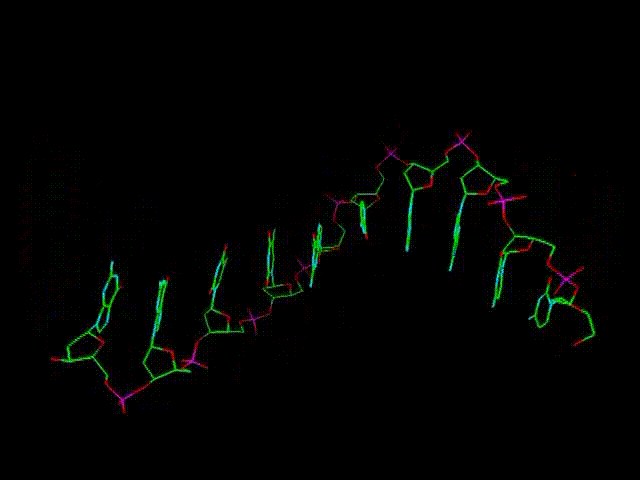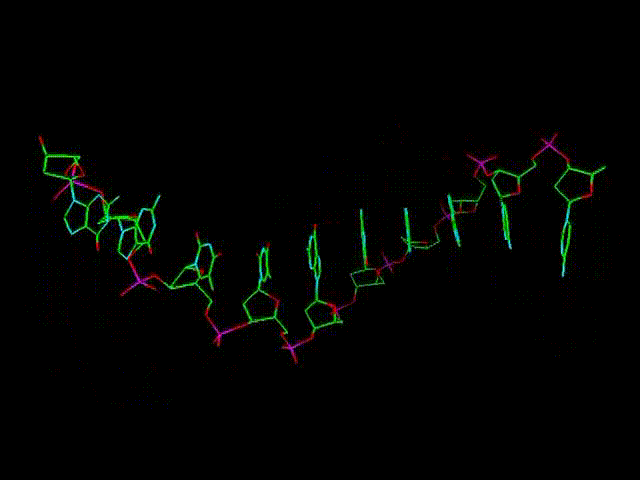
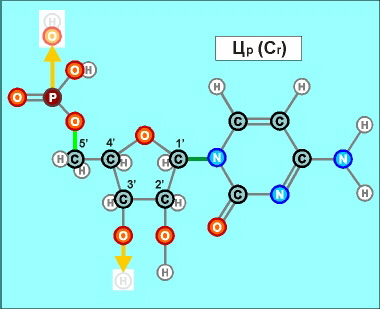
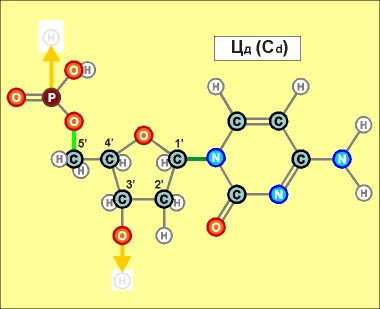
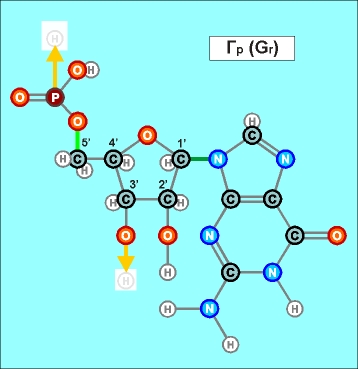
При этом
нуклеотиды урацилового ряда (обозначенные на предыдущих графических
материалах оттенками синего цвета и индексом r), рано или поздно
выстраиваются в рибонуклеиновую кислоту (РНК), а тиминового,
то есть, дезокси-ряда нуклеотидов (обозначенных на всех предыдущих
рисунках оттенками желтого и красного, а также индексом d), -
в дезокси-рибонуклеиновую - ДНК. (Причем, во втором
случае сразу происходит наращивание и второй, параллельной ее цепи,
см. далее).
Графически
универсальный продольный соединитель можно условно изобразить,
например, в виде шарового замка-защелки (подобного тем, которые используются
в детских пластмассовых конструкторах):
В условном
графическом представлении, для наглядности, соединители групп r и d показаны разного диаметра и цвета.
В последующих
графических построениях продольные соединители не показываются
для исключения чрезмерного загромождения рисунков, которое только мешало
бы пониманию процессов. Но их наличие постоянно подразумевается
по умолчанию.
Цепи ДНК
гораздо длиннее, чем РНК. Дополнительный отросток ОН, имеющийся в РНК,
несколько затрудняет процесс полимеризации (за счет некоторого размывания
и смещения электронного облака, см. движущуюся объемную модель выше),
и делает продольные связи РНК менее прочными.
Еще
одной теоретически возможной причиной этого может быть простой дефицит
хотя бы одного из компонентов этой группы, например, того же урацила.
Более точных объяснений этого явления автор
пока не установил и нигде не вычитал.
Со 100%-ной
уверенностью ясна лишь причина ограниченности длины РНК для матричных
РНК, копирующих информацию генов (см. ниже). Это строгая заданность
структуры ее начала и конца копируемым ею геном.
Дальнейшее
рассмотрение будем проводить, начиная с ДНК. Ее роль в образовании и
поддержании жизни, особенно, на первом этапе, все-таки, намного важнее.
А главное, - изначально она формируется из более простых (хоть
и не намного) составляющих.
При очень
длинных цепях, их подвижности и гибкости (из-за теплового фактора, наличия
оболочки, то есть ограничителя длины прямолинейного расширения и др.
причин), а также при постепенном снижении концентрации неохваченных
указанным процессом нуклеотидов, цепи могут замыкаться в кольца, а иногда
даже запутываться в узлы. Для этого только необходимо, чтобы конец
цепи случайным образом достаточно приблизился к ее началу.
Случай
случаем, но при таких длинных и произвольно ориентируемых на каждой
стадии образования цепях это вполне может происходить. Ничего сверхестественного
в этом, конечно, нет. Замыкание цепи ДНК в обычное кольцо, без узлов,
- еще и очень выгодное для ДНК состояние, как самое прочное.
Вместе с тем, это, все-таки, не строго обязательное условие образования
ДНК.
Может
показаться, что кольцевая структура ДНК делает невозможной ее самовоспроизведение.
Однако, в ее длинной цепи (исходной или вновь образовавшейся) всегда
найдется более слабый участок (например, из-за теплового воздействия
окружающей среды), который способен временно разорвать кольцевой
сцепление обеих ДНК и выпустить их в дальнейшую самостоятельную жизнь.
Хотя ничто не мешает обеим ДНК сосуществовать и в сцепленном
виде.
Как оказалось позже, размножаться способны даже ДНК, завязанные в
узлы.
Тема узловых ДНК слишком сложна и специальна, а для философского осмысления
процесса самообразования жизни совершенно не обязательна, поэтому
далее на данном сайте не рассматривается. Для самого общего представления можно только показать некоторые встречающиеся виды таких узлов (рисунок
позаимствован из источника свободного доступа - Википедии):
После замыкания
в кольцо цепь приобретает особую прочность и устойчивость, так как в
дальнейшем вся ее подвижность сводится к "утряске", то есть,
занятию всеми ее фрагментами и отдельными атомами наиболее устойчивых
в энергетическом смысле положений. При этом постепенно начинает формироваться
и пространственная структура цепи.
В
реальной ситуации одновременно (или чуть позже) с процессом наращивания
длины цепи идет еще и ее утолщение в 2 раза за счет формирования
параллельной цепи, соответствующей (но не равной!) первой. Причиной
этого является наличие в каждом нуклеотиде азотистого радикала (см.
представленные выше рисунки), стремящегося воссоединиться с другим,
подходящим ему (или, как принято говорить, комплементарным, ему).
Что
же это такое, комплементарность?
Не
надо пугаться этого якобы сложного слова. Его надо воспринимать как
комбинацию более простых, привычных и приятных слов комплект
и комплимент, что соответствует (случайно или специально - автору
не известно) и сути новообразованного слова:
|
Комплементарность
- особый тип соединения (в т.ч., химической связи) компонентов,
взаимно подходящих и дополняющих
друг друга
|
В
чем заключается эта "подходящесть", станет ясно из следующего
ее описания и поясняющих рисунков.
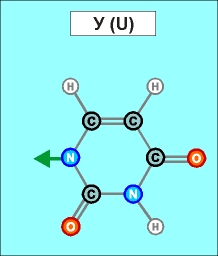
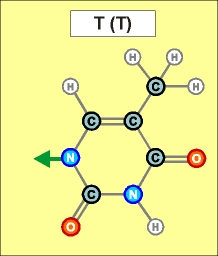
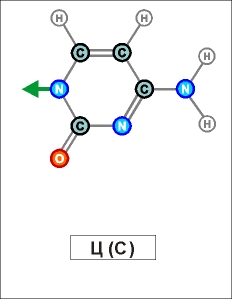
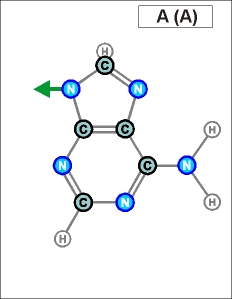
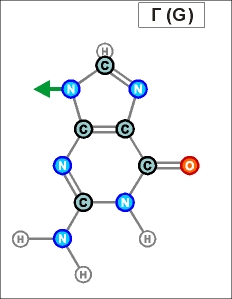
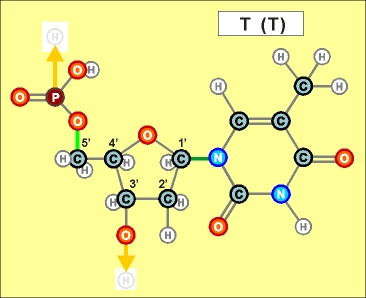
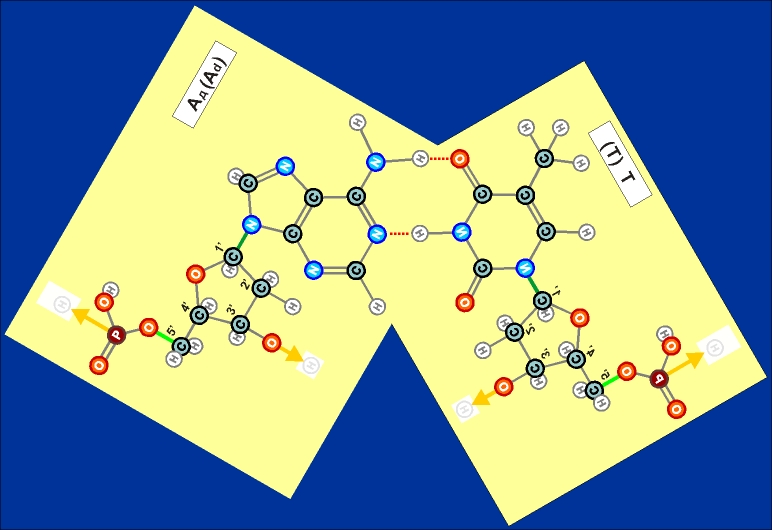
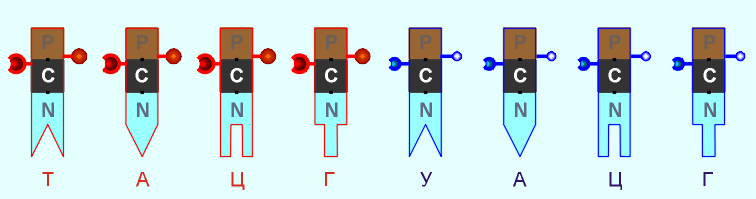
Как показано выше, два из нуклеотидов (Т и Ц) содержат по одному
азотистом кольцу , а два (А и Г) - по два кольца.
Одно
кольцо содержит и нуклеотид У. С точки зрения его строения он является
близким аналогом Т, но из-за большей степени окисления своего карбонатного
радикала может входить только в состав цепей РНК (как и РНК-овские
варианты А, Г и Ц).
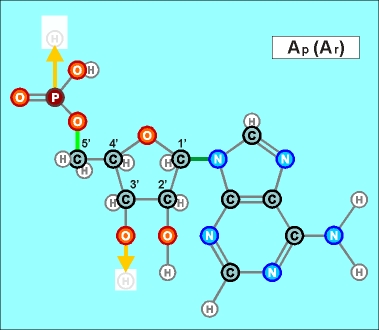
Свободные
нуклеотиды, оказывающиеся поблизости от одиночной (на первом этапе формирования)
цепи ДНК, притягиваются к ней сначала дополнительными атомами
азотистых колец таким образом, чтобы за их счет на исходных кольцах
как бы образовывалось(лись) еще одно, а то и два новых, связывающих
псевдо-кольца (см. рисунки 14.1 и 14.2, на которых они обозначены красным
пунктиром). Псевдо, - потому что в "полноценное" (и окончательное)
химическое соединение "чужие" азотистые кольца так и не вступают,
а только притягиваются друг к другу по принципу комплементарности
(см. выше). Такое сближение соответствует устойчивому состоянию
образующейся при этом пространственной структуры их двух нуклеотидов.
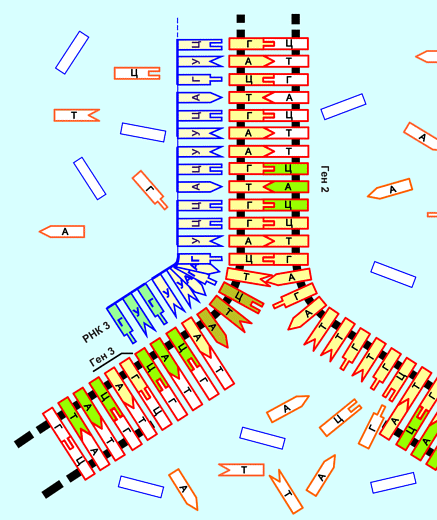
Рис.
12.1
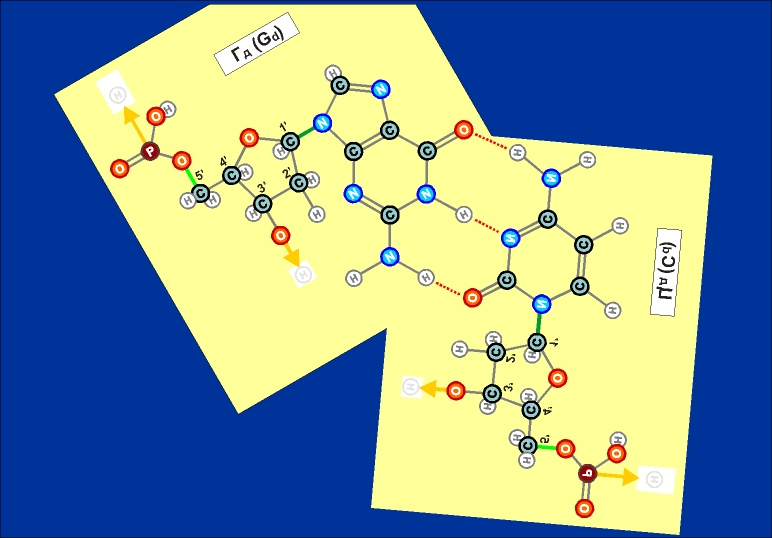
Рис.
12.2
Как
видно из этих рисунков, из-за
расположения и влияния "второстепенных",
дополнительных атомов при "главных" кольцах, боковой захват
возможен только между парами А - Т и Г - Ц (в РНК в первой
паре вместо Т взаимодействует его аналог У). Это и есть иллюстрацией
(и объяснением причины) комплементарности этих пар.
Одной
из молекул в каждой паре для такого взаимодействия приходится развернуться
(по отношению к изображенному в начальной части статьи рисунку), что
условно показано зеркальным отражением фрагментов Т и
Ц.
Из
этих же рисунков видно, что соединение А - Т (У - Т),
через две линии взаимодействия (и одно дополнительно возникающее
кольцо) значительно более слабое, чем соединение Г - Ц,
через три линии взаимодействия (и через два дополнительных кольца).
Таким
образом, допустимыми боковыми соединениями нуклеотидов (для их попарного
существования - главными) возможны только следующие (Таблица комплементарности):
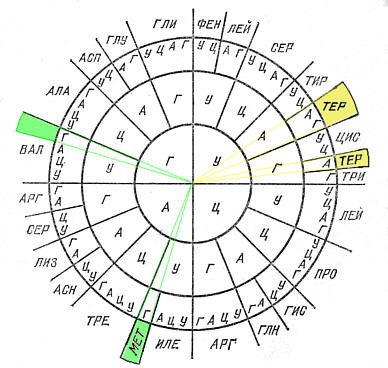
| Рис.13 |
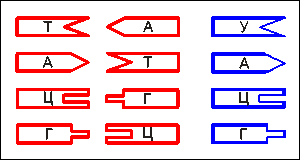 |
Справа
- нуклеотиды РНК
|
Очень
важным является то, что к любому нуклеотиду семейства ДНК (на рис. 13
- красные) могут присоединяться не только "свои" комплементарные
полу-пары, но и аналогичные нуклеотиды семейства РНК (У, А, Ц,
Г), обозначенные на рис.13 справа, синим цветом. Те, которые отвечают
принципу комплементарности. Например, к "красному" Т вполне
может присоединиться "синее" А; их соединители взаимно подходят
друг другу. Однако такие соединения бывают только временными
(из-за относительно слабой боковой связи между ними, которая, в свою
очередь, объясняется хоть и не очень значительным, но вполне конкретным
отличием в строении "красных" и "синих" нуклеотидов).
Но свою жизненно важную роль они еще сыграют (например, при копировании
участков цепи ДНК).
После
бокового присоединения любого нуклеотида к формируемой цепи он немедленно
соединяется через свой универсальный продольный соединитель еще и со
своим соседом, присоединившимся к цепи на мгновенье раньше, формируя
таким образом еще одну продольную цепь (ветвь), параллельную первой:
| ...-Т-Ц-Ц-А-А-Т-Г-Г-Г-Ц-Ц-Т-Т-А-Г-А-А-Т-..... |
| ....|
| | | | | | | | | | | | | |
| ...-А-Г-Г-Т-Т-А-Ц-Ц-Ц-Г-Г-А-А-
и.т.д. |
В пространстве
этот процесс (его небольшая часть) и получаемый продукт выглядит примерно так:

По
мере полного заполнения всех боковых "вакансий" образуется
двойная цепь, туго закрученная в спираль, см. рисунок в самом начале темы.
Это и есть молекула ДНК.
Еще
одной особенностью ДНК является противоположное по поляризации
(ориентации) направление ветвей (после завершения ее построения). Если
одна из них как бы идет вправо (или в любом другом направлении), то
другая - влево (или в любом другом направлении, противоположном первому).
Объяснить это можно, например, тем, что пентозно-фосфорные (карбонатно-фосфорные)
"отростки" нуклеотидов, идущие от нитратных основ (азотистых
колец), могут свободно вращаться относительно оси N - C (N - последний
атом нитратного кольца, С - первый атом карбонатной пентозы). Вот они
и занимают такое положение, при котором находящиеся на периферии нуклеотидов
фосфатные окончания, имеющие одинаковый заряд, находятся на максимальном
расстоянии друг о друга, за счет электростатического отталкивания. Оно
совсем невелико, но для смещения ничтожных масс фрагментов молекул вполне
достаточное.
Еще одна причина (или продолжение первой) - показанный ранее разворот одной из составляющих в каждой паре на 180 градусов, что только и делает возможным поперечные соединения.
(Это авторская версия этого явления. Более точное объяснение автору
не встречалось. Как и любое другое).
Автору
пока не совсем ясно, почему практически не создают двойных
цепей первичные, исходные, "природные" (не матричные) молекулы
РНК (за исключением примитивных вирусов). С этим еще предстоит разбираться.
(Возможно, из-за дефицита строительного материала. В частности, атомов
кислорода.)
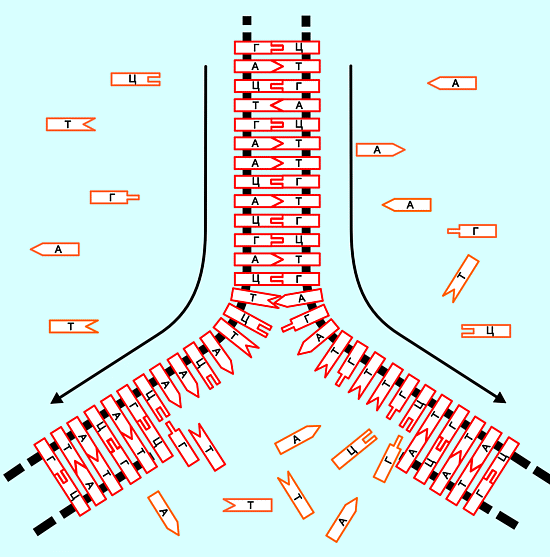
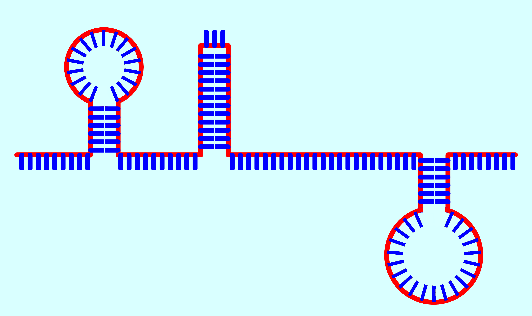
Зато
первичные (не матричные) РНК имеют интересное свойство частично "запутываться" и складываться
в отростки ("шпильки" или петли), если на небольшом расстоянии
цепи РНК попарно имеются отрезки, комплементарные друг другу, которые
и соединяются между собой (синим цветом на рис. 14 показаны нуклеотиды,
красным - образующаяся продольная нить):
 |
|
Рис.
14. Типичная РНК (упрощенная модель)
|
Пространственная
спираль ДНК - следствие не плоской и не абсолютно симметричной
(при виде с условного "верха") структуры исходных нуклеотидов,
а также создания продольных связей через разные атомы пентаз,
от т.н. 5-го атома углерода нижней пентазы (фактически - четвертого,
через дополнительный 5-й) к 3-му следующей верхней. Образующаяся спиралевидная молекула получает дополнительную устойчивость
еще и за счет этого.
Двойной
характер цепи ДНК - следствие бокового, а затем продольного сцепления
подключающихся к первичной цепи свободных нуклеотидов.
Замкнутые
в кольца ДНК способны закручиваться и в "сверхспирали", что
позволяет им быть прочными и очень компактными. Иллюстрацией сверхспирали
может служить многократно закрученная бельевая веревка или шнур пылесоса,
которые способны создавать произвольные самозакручивающиеся петли где-то
в их середине.
|
|
| .Многовариантность
ДНК и биологических видов |
Из описанного
выше процесса самообразования двойной спирали ДНК, состоящей
из случайной последовательности нуклеотидов, вытекает предположение
об огромной, чуть ли не бесконечной многовариантности таких первичных
ДНК. А такого, мол, нет и не может быть. Не наблюдаем мы бесконечного
количества видов ДНК (и образовавшихся на их основе биологических видов),
даже при помощи самых современных методов.
На самом
деле, практически наблюдаем. Несколько сот тысяч биологических видов
на Земле, включая растительный мир, животных всех видов, птиц, насекомых,
рыб, моллюсков, бактерий, микробов и вирусов - это очень большая многовариантность.
А ведь это - только ничтожная часть из всей первичной многовариантности
случайно образующихся ДНК из-за далеко не обязательной способности абсолютно
всех их к формированию живых организмов. Или, тем более, способных бороться
за выживание в бесконечно конкурентной среде. И, тем более, побеждающих
в этой борьбе. Только последние и есть то, что мы видим сейчас вокруг
себя .
Подавляющее
же большинство первичных ДНК достаточно короткие и относительно примитивные,
способные формировать только ничтожные комочки аминокислот - наипримитивнейшие
белки (см. далее), которые пригодны только для того, чтобы пойти в пищу
более сложным и совершенным.
Кстати,
ничто не мешает формироваться таким первичным (не наследственным) ДНК
и сейчас. Но они тоже в своем абсолютном большинстве просто поедаются
всеми, даже простейшими из уже сформировавшихся на сегодня видами, владеющими
биосферой Земли.
Но некоторые
(единицы), все-таки, и формируются, и выживают. В форме простейших новых
вирусов, агрессивных и вполне способных постоять за себя. Длина их ДНК
составляет "всего" несколько тысяч нуклеотидов.
|